예제.
ALTER SESSION SET STATISTICS_LEVEL = ALL;
SELECT * FROM EMPLOYEES
WHERE EMP_NO>10 AND FIRST_NAME LIKE 'Y%';
SELECT * FROM table(dbms_xplan.display_cursor(NULL,NULL,'ALLSTATS LAST'));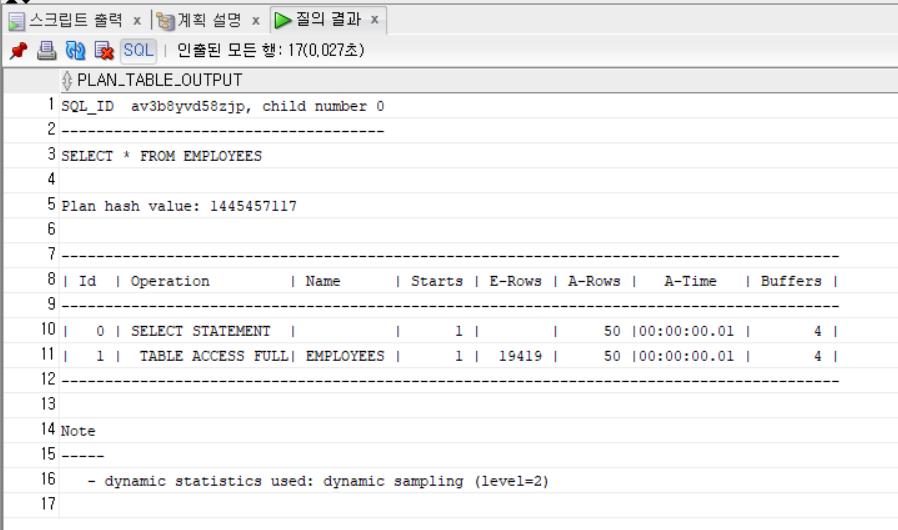
SELECT * FROM EMPLOYEES WHERE EMP_NO > 10 AND FIRST_NAME LIKE 'Y%'; 쿼리의 성능을 튜닝하려면 여러 가지 방법을 고려할 수 있습니다. 여기서는 쿼리 성능을 개선할 수 있는 몇 가지 접근 방법을 설명하겠습니다.
1. 인덱스 활용
- 이 쿼리에서 EMP_NO와 FIRST_NAME 컬럼에 조건이 걸려 있기 때문에, 적절한 인덱스를 생성하면 성능을 크게 향상시킬 수 있습니다.
(1) EMP_NO 컬럼 인덱스
- EMP_NO > 10 조건은 일반적으로 인덱스를 활용하여 빠르게 필터링할 수 있습니다. EMP_NO 컬럼에 인덱스가 없으면, 전체 테이블을 스캔해야 하므로 성능이 저하됩니다.
CREATE INDEX idx_emp_no ON EMPLOYEES(EMP_NO);
(2) FIRST_NAME 컬럼 인덱스
- FIRST_NAME LIKE 'Y%' 조건은 LIKE 연산자가 접두어 검색일 경우 인덱스를 사용할 수 있습니다. 이는 'Y'로 시작하는 이름들을 빠르게 찾을 수 있게 해줍니다.
CREATE INDEX idx_first_name ON EMPLOYEES(FIRST_NAME);
LIKE 조건이 접두어로 시작하는 경우(즉, 'Y%'와 같은 형태) 인덱스를 효과적으로 사용할 수 있습니다. 반면, LIKE '%Y'와 같은 형식은 인덱스를 사용할 수 없으므로 성능 최적화가 어려워집니다.
(3) 복합 인덱스
- EMP_NO와 FIRST_NAME 두 조건이 모두 사용되므로, 두 컬럼을 포함하는 복합 인덱스를 추가하면 더 효율적인 쿼리 실행이 가능할 수 있습니다. 이 인덱스는 두 조건을 모두 고려하여 검색을 최적화할 수 있습니다.
CREATE INDEX idx_emp_no_first_name ON EMPLOYEES(EMP_NO, FIRST_NAME);
2. 쿼리 리팩토링
SELECT *는 성능을 저하시킬 수 있습니다. 데이터베이스가 모든 컬럼을 반환해야 하므로, 필요한 컬럼만 지정하는 것이 더 효율적입니다.
예시:
SELECT EMP_NO, FIRST_NAME, LAST_NAME FROM EMPLOYEES WHERE EMP_NO > 10 AND FIRST_NAME LIKE 'Y%';
이렇게 필요한 컬럼만 선택하면, 데이터 전송량이 줄어들어 성능이 개선됩니다.
3. EXPLAIN 사용하여 실행 계획 확인
실행 계획을 확인하여 쿼리가 어떻게 실행되고 있는지 분석하는 것이 중요합니다. EXPLAIN을 사용하면 쿼리 실행 계획을 볼 수 있습니다. 이를 통해 인덱스를 제대로 활용하고 있는지, 어떤 연산자가 사용되고 있는지 알 수 있습니다.
EXPLAIN SELECT * FROM EMPLOYEES WHERE EMP_NO > 10 AND FIRST_NAME LIKE 'Y%';
실행 계획에서 인덱스를 제대로 사용하고 있는지 확인하고, 만약 테이블 스캔(Table Scan)이 발생한다면 인덱스를 추가하거나 쿼리를 다시 최적화할 필요가 있습니다.
4. 통계 최신화
인덱스를 추가한 후, 데이터베이스에서 통계 정보를 최신화하는 것이 중요합니다. 데이터베이스가 통계 정보를 사용하여 최적의 실행 계획을 생성하므로, 통계가 오래되면 비효율적인 실행 계획을 생성할 수 있습니다.
ANALYZE TABLE EMPLOYEES;
이 명령은 테이블의 통계 정보를 최신화합니다.
5. 쿼리 조건 재구성
- EMP_NO > 10 조건은 효율적인 필터링이 가능합니다. FIRST_NAME LIKE 'Y%' 조건에 비해 상대적으로 성능에 큰 영향을 주지 않지만, 두 조건을 결합할 때는 EMP_NO의 범위가 좁은 경우 먼저 처리되도록 할 수 있습니다.
6. 결과 캐싱
- 자주 실행되는 쿼리라면 결과를 캐시하거나, 적절한 인덱스를 사용하여 반복적인 쿼리 성능을 향상시킬 수 있습니다. 이 방법은 특히 동일한 쿼리가 반복될 때 유용합니다.
최종 최적화된 쿼리 예시
CREATE INDEX idx_emp_no_first_name ON EMPLOYEES(EMP_NO, FIRST_NAME);
SELECT EMP_NO, FIRST_NAME, LAST_NAME
FROM EMPLOYEES
WHERE EMP_NO > 10 AND FIRST_NAME LIKE 'Y%';
이렇게 인덱스를 추가하고, 필요한 컬럼만 선택하도록 쿼리를 최적화하면 성능이 개선될 것입니다.
결론
위의 방법들을 적용하여 SQL 쿼리를 최적화할 수 있습니다. 주로 인덱스 추가와 쿼리 리팩토링을 통해 성능을 크게 향상시킬 수 있습니다. 실행 계획을 확인하고 필요한 인덱스를 추가하며, 필요하지 않은 데이터는 제외하는 방식으로 최적화를 진행하는 것이 좋습니다.
'데이터베이스 DB' 카테고리의 다른 글
| VIEW PUSHED PREDICATE (0) | 2024.12.17 |
|---|---|
| 오라클 환경셋팅, 오라클 다운로드 방법 (0) | 2024.12.17 |
| SQL 실행 계획 분석하기 (1) | 2024.12.17 |
| SQL 튜닝 관련 단어 및 예상 문제 (1) | 2024.12.16 |
| 인덱스 설정 기준 및 SQL 작성법 (0) | 2024.12.16 |

댓글